O desafio
- Autor: snwo
- Descrição: Welcome to assembly zoo
Análise inicial
Dando uma olhada no contrato de setup,
vemos que o objetivo final é
setar a variável isSolved no contrato ZOO para 1.
| |
Logo de cara,
ZOO tem alguns pontos interessantes.
Esse contrato implementa Pausable
e chama a função _pause no final do construtor.
Usando a documentação,
vemos que isso é um mecanismos pra habilitar/desabilitar funções do contrato.
Quando pausado,
funções marcadas com o modificador whenNotPaused
chamam revert ao serem chamadas.
| |
Seguindo a diante,
esbarramos na função commit,
que usa esse modificador.
Essa função também tem a peculiaridade
de ser escrita completamente em assembly.
Ok…
Vamos ignorar ela por enquanto,
mas aparentemente a gente tem que despausar o contrato pra chegar nela.
| |
Por fim,
temos uma função fallback.
Essa função é especial (por isso não precisa da keyword function)
e é chamada quando a assinatura especificada no calldata não existe.
Basicamente, é a função que é chamada quando você chama uma função que não existe.
Pra nossa infelicidade,
basicamente tudo é escrito em assembly,
e não é pouco código não.
Vamos analisar o que não está em assembly então:
- A função aceita
bytescomo argumento. Esses bytes são na verdade a calldata enviada para a função. - Temos um array de
function(bytes memory)chamadofunctions. - O único elemento desse array é a função
commitque vimos antes. commité então chamada a partir desse array no final da função
| |
Se você já tem alguma experiência com desafios de pwn,
esse array functions tá quase que gritando
“ME CORROMPA POR FAVOR”.
A única razão lógica pra
chamar a função usando o array é
justamente pra você conseguir corromper o endereço.
O código não foi escrito assim por acaso.
O fato de o que vem logo depois estar em assembly
(único lugar que bugs de memória podem acontecer em Solidity)
só enfatiza isso.
Nesse contexto,
sem nem ler o assembly nem nada,
o caminho já tá mais ou menos claro:
deve ter algum bug no assembly que me permite sobrescrever o array.
Sobrescrevendo o array,
a gente provavelmente consegue pular direto pra commit
e bypassar o whenNotPaused.
O que a gente faz quando chegar lá?
Menor ideia,
um problema de cada vez.
Dito isso, hora de sofrer tentando entender o assembly. Mas, antes disso, vamos entender um pouco sobre como assembly em Solidity funciona.
Yul
Todo código que roda na Ethereum Virtual Machine (EVM) tem que ser compilado para bytecode da EVM. Como o nome diz, a EVM é uma máquina virtual e tem sua própria arquitetura, exatamente como x86 e ARM. Como toda arquitetura, a EVM tem instruções e essas instruções podem ser representadas mais facilmente a partir de assembly. Uma curiosidade interessante é que todos os opcodes da EVM ocupam exatamente 1 byte. Elegante, né?
Bom, você pode escrever código pra EVM
instrução por instrução,
mas felizmente isso não é necessário.
Esses blocos assembly usados em Solidity
na verdade aceitam uma linguagem chamada Yul,
que é tipo um assembly turbinado.
Em Yul,
você chama as instruções normalmente,
mas também existem loops, condicionais e variáveis.
Isso facilita bastante e
meio que abstrai a arquitetura de pilha da EVM.
Você ainda consegue acessar as instruções diretamente,
mas aquela parte mais chata e repetitiva de escrever assembly é feita pra você.
Como funciona a memória de um contrato na EVM
Primeiro de tudo,
um ponto super importante:
a EVM é uma máquina de 256 bits.
Sendo assim,
a stack tem entradas de 32 bytes e
os endereços ocupam 32 bytes.
Não é à toa que
uint e uint256 são sinônimos em Solidity:
basicamente tudo é feito de 32 em 32 bytes.
Outro fato interessante é que a memória de um contrato começa em 0. Conforme o contrato vai usando memória, ela vai sendo expandida (e isso custa gas).
Temos também que
as quatro primeiras words (word = 32 bytes)
são reservadas e têm usos específicos.
Nessa lógica,
o espaço livre pro contrato fazer o que quiser
começa em 0x80.
| |
Dessas words reservadas,
a mais importante é a terceira (fica em 0x40).
Nesse espaço fica o free memory pointer.
Esse ponteiro aponta pra onde tem memória livre.
Dessa forma,
sempre que o programa precisa armazenar alguma coisa na memória,
ele armazena no local onde esse ponteiro aponta
e então move o ponteiro adiante pra algum lugar livre.
Com todo esse contexto explicado, vamos partir pra análise do assembly.
A função fallback
Primeiro a função usa mload
pra pegar um endereço disponível no free memory pointer.
Em seguida,
armazena o tamanho e o conteúdo da calldata nesse espaço.
Lembrando aqui que a calldata nesse contexto
é exatamente a mesma coisa que o argumento passado pra função.
| |
Em seguida,
aquela variável de fora do assembly, local_animals,
é alocada em um espaço de 0x120 bytes.
| |
Temos então um loop pra iterar
cada byte da calldata.
Em seguida,
o primeiro byte da calldata é lido e salvo em op.
Essa sequência de mload shr add
vai se repetir bastante.
A variável op é então usada em um switch.
Com isso,
podemos ver que o que o assembly faz é basicamente
ler instruções passadas via calldata,
sendo o primeiro byte
qual instrução queremos chamar.
| |
Vamos analisar em seguida
as operações 0x10 e 0x20.
A 0x30 será ignorada
porque não foi usada na solução desse chall.
Ainda assim,
foram postadas soluções diferentes no Discord do CTF
que usam essa instrução.
Operação 0x10 - Add animal
O próximo byte da calldata é armazenado em idx.
Pelo nome,
já vemos que isso vai ser um índice.
Em seguida,
o código checa se o índice é maior que 7.
Se for,
a transação falha.
| |
Os próximos 4 bytes
são pra name_length e animal_index,
cada um com 2 bytes.
| |
O código segue pra alocar um espaço e o chama de temp.
Na primeira word,
animal_index é armazenado.
| |
Temos em seguida um mcopy
que copia os próximos name_length bytes da calldata
pra terceira word de temp.
| |
O valor em name_length é então alinhado
e armazenado na segunda word de temp.
| |
Agora que animal_index, name_length e name foram escritos na memória,
o free memory pointer é atualizado pra apontar pra logo depois deles.
| |
O endereço de temp segue para ser armazenado
em (local_animals + 0x20) + (idx * 0x20).
Com isso, vemos que local_animals
é na verdade um array,
com o endereço de seus elementos começando em + 0x20.
| |
Por fim,
vemos que a primeira word de local_animals
é o tamanho do array.
| |
Vamos desenhar o que acabamos de descobrir então. Abaixo temos o layout do array:
| |
E abaixo temos o layout de um dos elementos.
Note que animal_index e name_length
são lidos como números de 2 bytes da calldata,
mas armazenados como números de 32 bytes:
| |
Conclusão:
a operação 0x10 recebe os argumentos
idx, animal_index, name_length e name da calldata,
aloca e preenche um animal com esses valores,
e adiciona ele no array local_animals no índice idx.
Operação 0x20 - Edit animal
Entrando no case da operação 0x20,
temos o mesmo início da operação anterior:
o primeiro byte vai para o idx (que não pode ser maior que 7).
O resto do case pega o próximo byte e o chama de edit_type.
Em seguida,
temos um outro switch que se separa em dois valores para edit_type:
0x21 e 0x22.
Não vamos falar sobre o 0x22,
pois ele não foi utilizado na solução.
Quando edit_type é 0x21,
o contrato lê 2 bytes para name_length e
em seguida copia os name_length bytes seguintes
pra sobrescrever o name do animal sendo editado.
O ponto mais interessante aqui é que
o name_length anterior não é verificado,
então podemos editar um animal com um name maior que o anterior,
ou seja, um overflow para o animal de baixo.
| |
Sobrescrevendo o array functions
Fazendo esse desafio,
eu demorei bastante tempo pra pensar numa forma
de sobrescrever o array functions.
Afinal, o overflow que encontramos na edição de animais
simplesmente não alcança o array,
porque ele vem antes dos animais.
Pra entender melhor onde as coisas se situam na memória,
podemos usar o debugger do foundry.
Pra isso,
basta criar um projeto novo com forge init
e criar um teste.
Como teste,
vamos criar um animal com:
idx = 0x00name_length = 0x0005index = 0xaabbname = 0x1122334455
Com a análise da função fallback que fizemos,
vemos que basta mandar essa sequência de bytes: 10000005aabb1122334455.
Dessa forma,
nosso contrato só precisa chamar fallback
e passar esses bytes como argumento.
Como fallback na verdade não é exatamente uma função,
temos que usar call e passar nossos bytes pra ele.
| |
Se rodarmos o teste, vemos que ele falhou
porque a função EnforcedPause() foi chamada.
Isso é esperado,
já que commit foi chamada normalmente e o contrato estava pausado,
como vimos antes.
| |
Pra debugar,
é só mudar o comando pra forge test --debug test_bypass_pause.
Isso vai abrir o debugger do foundry,
que nos permite executar o programa passo a passo
e ver o que exatamente tá na memória.
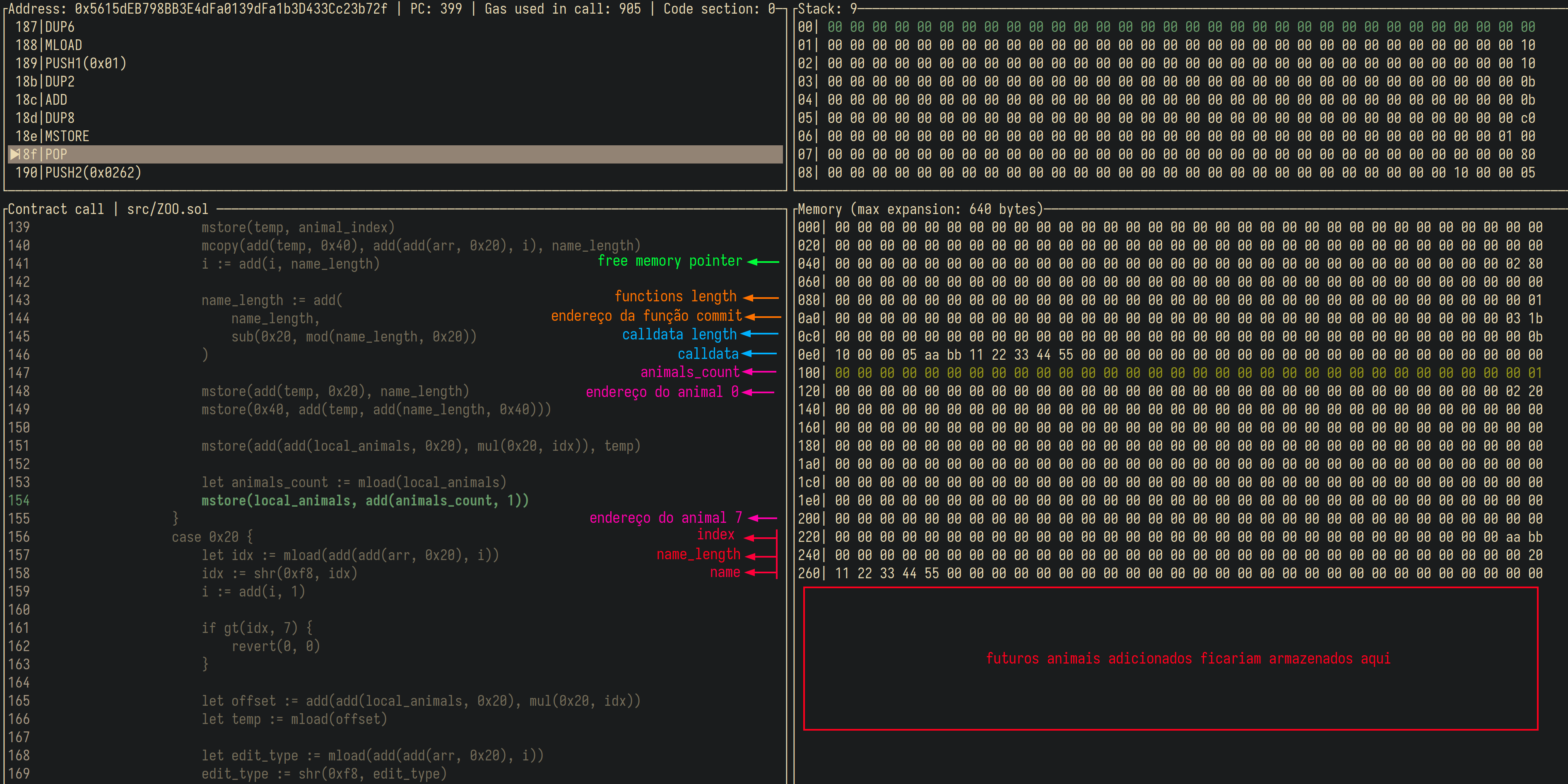
Abaixo eu parei o programa logo depois
do mstore que incrementa animals_count
na hora de adicionar o animal.
A overview da memória que o foundry mostra
é meio assustura a princípio por conta da quantidade de números em cada linha,
mas a lógica é exatamente a mesma do que você veria debugando x64.
A diferença é que ao invés de 8 bytes por linha, são 32.
Na screenshot, basicamente tudo que o programa fez está marcado.
Dessa forma,
fica fácil de ver que o overflow na hora de editar um animal
não serviria pra sobrescrever functions,
porque esse array fica bem antes de onde os animais ficam.
Usando animais não inicializados como trampolim pra bypassar o whenNotPaused
Na screenshot do debugger que vimos, chama atenção o fato de quase todo o array de animais estar zerado. Isso acontece porque só adicionamos um animal no índice 0, os outros índices ficam zerados por padrão, sem serem inicializados.
Na verdade,
o código nunca checa de fato se um animal foi inicializado antes de acessá-lo.
O que aconteceria então se editássemos um animal que não foi inicializado?
Usando a screenshot como base,
o segundo animal não foi inicializado.
Se passarmos idx=0x01,
temp será o endereço desse animal,
no caso o endereço que é todo zeros.
| |
Na hora de copiar o nome,
ele será copiado para 0x00 + 0x40,
que é 0x40,
o free memory pointer.
| |
Dessa forma,
conseguimos escrever qualquer coisa de 0x40 pra baixo,
incluindo 0xa0,
que é onde o endereço da commit fica.
Ainda assim,
temos algumas questões a resolver,
porque somos obrigados a escrever por cima
de outros valores para chegar em 0xa0.
Vamos revisar eles um a um:
0x40- Esse é o free memory pointer. Intuitivamente, podemos escrever aqui qualquer coisa maior (mas não MUITO maior) ou igual ao valor original que tudo deve dar certo.0x60- Esse endereço é na verdade sempre zerado. Podemos simplesmente escrever zero aqui então.0x80- Esse é o tamanho do array functions. Só escrever0x01aqui pra não mudar nada.
Sem problemas então,
já sabemos o que escrever em cada endereço
antes de chegar em 0x0a.
Agora a questão é,
o que escrever em 0x0a?
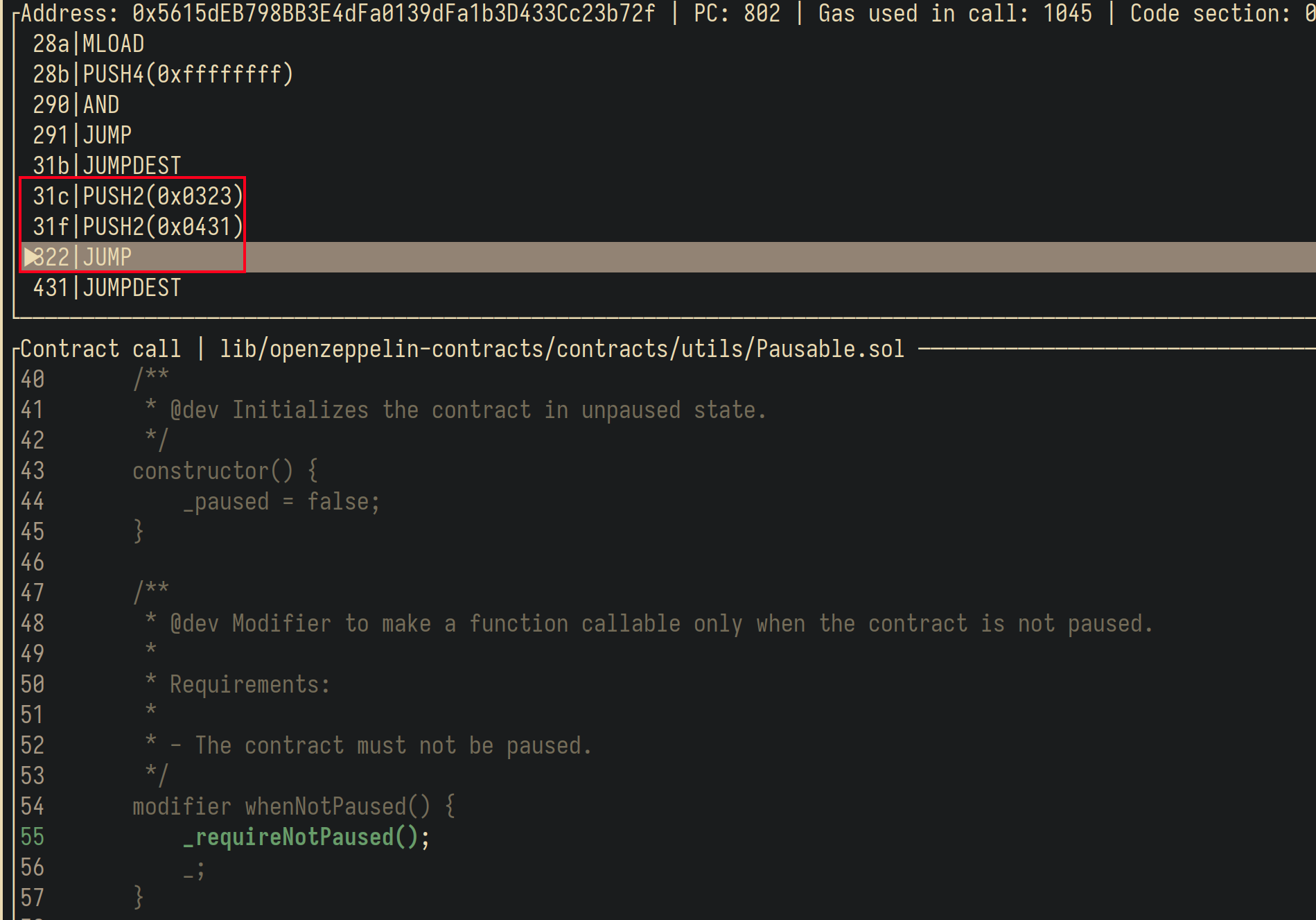
Com o debugger,
podemos ver que o endereço que estava originalmente lá
vai para a função whenNotPaused,
do contrato Pausable.
A primeira linha chama _requireNotPaused,
que é a função que chama revert se o contrato estiver pausado.
Basta então pular para onde essa função retornaria.
Usando o debugger,
fica fácil ver que esse endereço é 0x0323.
Finalmente,
podemos montar nosso payload pra bypassar o whenNotPaused.
0x20(1 byte), pra editar um animal.0x07(1 byte), pra escolher o último índice (poderia ser qualquer um).0x21(1 byte), pra escolher oedit_type.0x80(2 bytes), porque vamos escrever 128 bytes.0xffff(32 bytes), pra sobrescrever o free memory pointer.0x00(32 bytes), pra sobrescrever o endereço que sempre tem zeros.0x01(32 bytes), pra sobrescrever o tamanho do array functions.0x0323(32 bytes), que é o endereço pra onde queremos pular.
Payload: 2007210080000000000000000000000000000000000000000000000000000000000000ffff000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000000323
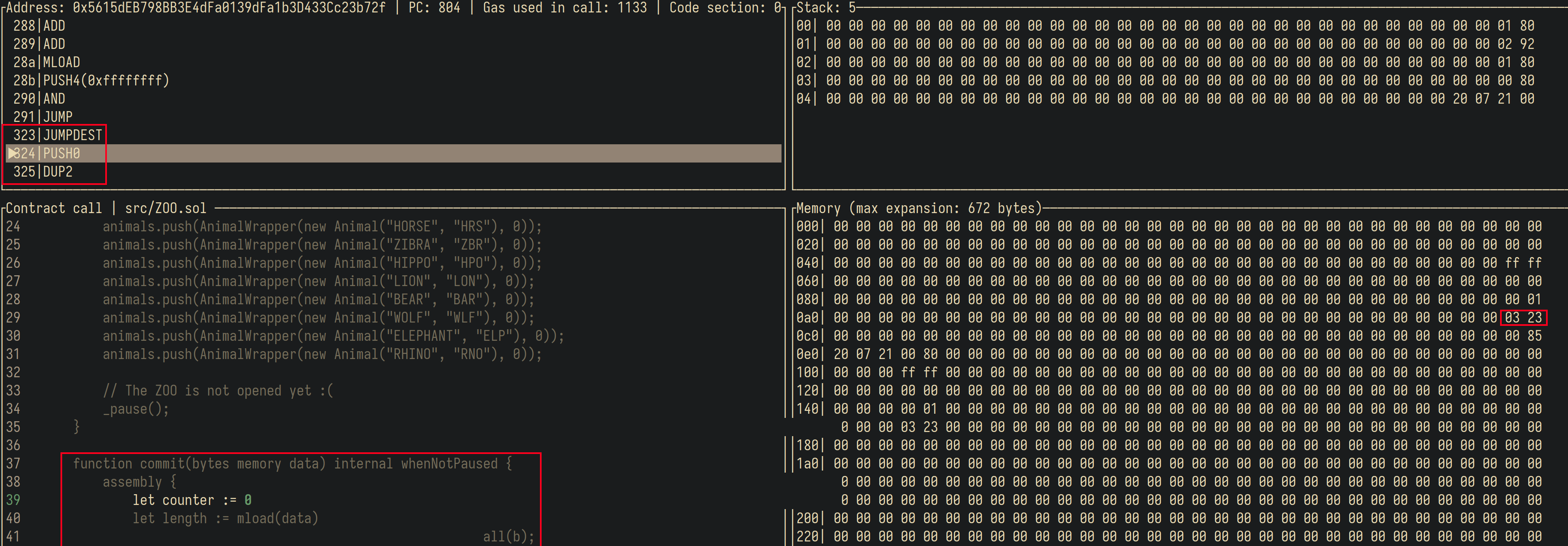
Depois de atualizar o contrato teste com esse payload e rodar o teste, vemos que agora não temos mais o erro dizendo que o contrato tá pausado.
| |
Com o debugger,
também é possível verificar que o valor foi sobrescrito
e que agora o contrato está entrando na função commit.
Objetivo final = sstore(1,1)
Ótimo,
conseguimos com sucesso bypassar o WhenNotPaused.
E agora?
Agora a gente tem que descobrir
uma forma de sobrescrever a variável isSolved.
Pra isso, vamos revisar como ela foi declarada primeiro:
| |
Essa variável não está na memória,
ela pertence ao contrato em si
e é armazenada na própria blockchain.
Variáveis desse tipo ficam armazenadas no que chamam de storage.
Pra interagir com essas variáveis,
temos as instruções sload e sstore.
A primeira pra ler e a segunda pra escrever.
Cada uma dessas variáveis fica armazenada em um slot,
que é referenciado usando um número de 32 bytes.
Nos casos mais simples,
tipo de um simples uint256,
o número do slot simplesmente vai incrementando de 1 em 1 a partir do zero
(a primeira variável ficaria no slot 0, a segunda no 1 e assim por diante),
mas tem uns casos mais enrolados
em que não é tão simples assim.
Enfim,
esse caso é simples e isSolved fica no slot 1.
Não é no 0 porque na verdade tem uma variável escondida que armazena
se o contrato está pausado ou não meio que implícita.
Precisamos então setar a variável no slot 1 para 1.
Isso seria sstore(1,1) em assembly.
Vamos então analisar o assembly da commit
e ver como isso poderia ser possível.
Relaxa que essa é menor que a fallback.
A função commit
Primeiro vamos lembrar que
o único argumento dessa função se chama data
e é aquele array que a fallback constrói.
Sendo um array,
a primeira coisa que a função faz é loopar
cada elemento dele.
De agora em diante todos os trechos
serão uma iteração desse loop.
| |
Dentro do loop,
o index e name_length do animal são lidos.
Detalhe que nessa função o index do animal é chamado de idx,
o que tinha um significado diferente na outra função.
Meio confuso,
mas não fui eu que escrevi o código.
| |
Agora eu vou pular umas boas linhas de código
que não fazem nada de relevante pra solução
e ir direto ao ponto.
Atenção aqui que esse é o pulo do gato.
Temos uma varíavel slot_hash,
que é o hash de um trecho de memória.
Aqui o valor da variável não é super importante,
só é importante saber que é um número previsível.
Temos também uma variável animal_counter,
que é lida do storage usando sload.
O slot do qual essa variável é lida depende de idx,
um valor que a gente controla.
O ponto importante aqui é que se sload recebe
um slot nada a ver,
que não tem nada,
ele retorna 0.
| |
Por fim,
temos o tão esperado sstore.
Só precisamos transformar os dois números que ele recebe em 1
e o chall está resolvido.
O segundo argumento é fácil,
praticamente qualquer valor de idx vai
fazer com que animal_counter seja 0,
e 0+1=1, QED.
O primeiro argumento é um pouco (muito) mais enrolado,
mas a gente chega lá.
| |
Primeiro de tudo,
a gente realmente controla idx?
Esse número é aquele primeiro campo que cada animal tem,
e se você lembrar bem ele é armazenado em 32 bytes,
mas a função fallback na verdade só aceita números de 2 bytes pra esse valor.
Isso quer dizer que normalmente 0 <= idx < 2^16,
o que simplesmente não vai funcionar.
Pra gente transformar aquele primeiro argumento em 1,
com certeza precisamos controlar os 32 bytes do idx.
Em busca dos outros 30 bytes de idx
Precisamos de uma forma de
escrever um número qualquer de 32 bytes
no idx de um animal.
Tendo como base o caminho tomado até agora,
a primeira maneira de fazer isso
que veio à minha cabeça seria
usar o overflow na operação de edição do nome do animal.
Por exemplo,
uma forma seria criar dois animais
e depois editar o nome do primeiro
com um nome mais longo que o original,
sobrescrevendo o que vem logo depois,
que seria o idx do segundo animal.
Não tem nada de errado com essa lógica,
mas essa ideia não funciona.
Não funciona porque a parte do código
que edita o animal tem um bug
que não permite que você chame a operação de edição
mais de uma vez.
Se você reparar,
depois do mcopy,
o valor de i não é incrementado,
então as próximas instruções acabam sendo lidas
do novo nome do animal.
Não sei se o autor do chall esqueceu de incrementar o i
ou se isso foi de propósito,
mas isso meio que quebra a ideia de
usar a edição pra corromper
o idx do animal seguinte.
| |
Outra ideia seria simplesmente aproveitar
o overflow que a gente usou pra sobrescrever functions.
A gente seguiria corrompendo a memória,
até chegar no idx do primeiro animal.
Isso também não funciona.
Se você revisar o layout da memória que vimos antes,
vai reparar que a calldata fica armazenada
entre o início de onde conseguimos corromper (0x40)
e onde ficaria o idx do primeiro animal (0x220).
Isso significa que se o payload aumentar,
a distância até onde queremos corromper também aumenta,
porque a calldata é o nosso payload.
Por conta disso é impossível corromper
qualquer coisa que vier depois da calldata usando esse método.
A solução foi usar um outro overflow que não vimos ainda.
No final da operação que adiciona um animal,
a variável animals_count é incrementada.
Acaba que na verdade não tem nada que
verifica se o index onde você está adicionando um animal já está ocupado
ou se mais de 8 animais foram criados,
então é possível fazer animals_count ter um número
bem maior que o tamanho do array.
É só sair criando animais
que essa variável vai sendo incrementada.
| |
Por que isso é útil?
Porque o loop na função commit
itera animal_count vezes.
A intenção desse loop é
iterar cada elemento do array,
com cada iteração lendo o endereço de um animal.
Se animal_count for maior que o array,
o loop vai começar a ler o conteúdo dos animais em si,
que a gente controla.
A ideia então seria criar um animal
cujo idx é o endereço do seu próprio nome.
Assim, quando o loop vazar do array e chegar no primeiro animal,
ele seguiria o ponteiro e acharia que o idx
desse animal é o nome que a gente escolheu.
Como o nome não tem limite de tamanho,
a gente consegue setar ele pra um número de 32 bytes sem problema.
A gente só consegue controlar os 4 bytes menos significativos do idx,
mas isso não é um problema,
porque o endereço que a gente precisa escrever não é um número grande.
Abaixo é mostrado como a memória fica fazendo isso.
Em vermelho temos o array,
mas note que animal_count tem o valor 9,
que é maior que o tamanho do array.
Logo depois do array,
temos o primeiro animal,
cujo idx é igual ao endereço do seu nome (0x320).
No nome,
armazenamos o número que queremos que a função commit
interprete como o idx de um animal.
Quando a função commit recebe esse array,
ela vai iterando começando com o endereço do animal 0.
Como animal_count é 9,
ela então passa do array até chegar em 0x2e0.
A função interpreta esse número como se fosse
o endereço do animal 8,
que na verdade nem existe.
Seguindo o ponteiro,
ela chega em 0x2e0,
cujo valor controlamos.
Como os primeiros 32 bytes de um animal são seu idx,
a função vai achar que 0x320 na verdade
é o idx do animal 8.

Montar esse esquema não é tão complicado quanto parece.
Abaixo temos uma função em Python que gera o hexa do primeiro animal.
Aqui não tem nada de muito misterioso,
simplesmente criamos um animal normalmente
com os valores corretos.
idx precisa ser o endereço onde o nome vai ficar
e o nome vai ser o valor que queremos
que o animal 8 tenha como idx.
Vamos ver como chegar nesse número em breve.
| |
Depois disso precisamos criar animais vazios
pra incrementar animal_count.
A seguinte função faz exatamente isso.
Aqui criamos vários animais iguais no mesmo índice
e com um nome vazio.
O objetivo aqui é realmente
só incrementar animal_count,
os valores em si não importam muito.
| |
O número mágico
Agora sim,
controlamos todos os 32 bytes de idx.
Pra que que servia isso mesmo?
Ah sim,
temos que setar o primeiro argumento do sstore pra 1.
| |
Temos que achar um número idx tal que
slot_hash + (2 * idx) + 1
seja 1.
Isso a princípio parece impossível porque
a única solução seria idx = 0
com slot_hash = 0,
e a gente não controla slot_hash,
ele é um número gigante full aleatório.
Parece impossível,
mas só até você lembrar
que estamos no mundo dos computadores,
especificamente na EVM,
onde 2^256 = 0.
Sim, eu estou falando de overflows.
Nós vamos transbordar (2^256)-1
e fazer o número dar a volta e cair exatamente em 1.
A conta é bem tranquila de fazer com a shell do Python.
m é o maior número possível na EVM (256 bits) e
h é o slot_hash (peguei usando o debugger).
| |
E assim,
43344706377821576760468996987613231211325356002982170351334206299952371618457
é o nosso número mágico
que vai colocar 1 no primeiro argumento do sstore.
Finalizando
Nosso payload final vai ser o seguinte então:
create_evil_animal- Criamos um animal cujoidxé o endereço do seu nome. No nome, colocamos o número mágico.create_empty_animals- Criamos vários animais vazios pra incrementaranimal_count.overwrite_ret- Usamos a edição de nome pra sobrescrever o arrayfunctions, bypassando owhenNotPaused.
O payload é longuinho e fazer tudo na mão seria tedioso, então eu fiz um script pra montar ele bonitinho:
| |
Rodando esse script obtemos:
| |
Colocando esse valor no nosso contrato de testes,
vemos que deu tudo certo e isSolved foi setado pra 1 como queríamos.
| |
Na hora de resolver o chall no CTF de verdade,
podemos usar o cast send pra mandar nosso payload como calldata.
| |
Flag: SEKAI{super-duper-memory-master-:3}